Ein Fall für Index
Ein Kunde in einem der Projekte beklagte sich darüber, wie lange eine bestimmte Aktion dauerte. Ganze 17 Sekunden vergingen, bis die neuen Werte von der Applikation verarbeitet wurden. Das war inakzeptabel – besonders dann, wenn viele Änderungen dicht aufeinanderfolgten.
Konkret geht es in der Applikation um eine sogenannte Geostruktur. Die Struktur ist hierarchisch und beginnt beispielsweise mit einem Gebäudekomplex. Dieser lässt sich aufteilen in einzelne Gebäude, diese wiederum in Stockwerke, welche Räume und Korridore haben. Stelle dir nun den Fall vor, bei dem die Beschriftungen aller Räume ändern. Jede Änderung muss gegen die anderen Räume auf Integrität geprüft werden (beispielsweise keine doppelten Raumnummern). Im konkreten Fall bestand der Datensatz aus 10'000 Räumen und Korridoren.
Der erste Schritt bei jeder Performance-Optimierung ist die Messung. Der Teil des Programms, der auf dem Server läuft und die Anfragen verarbeitet, ist in Java programmiert. Um zu untersuchen, wo das Bottleneck ist, habe ich einen sogenannten Profiler eingesetzt. Der Profiler VisualVM für Java erlaubt es, genau herauszufinden, welcher Teil im Programmcode wie lange benötigt.
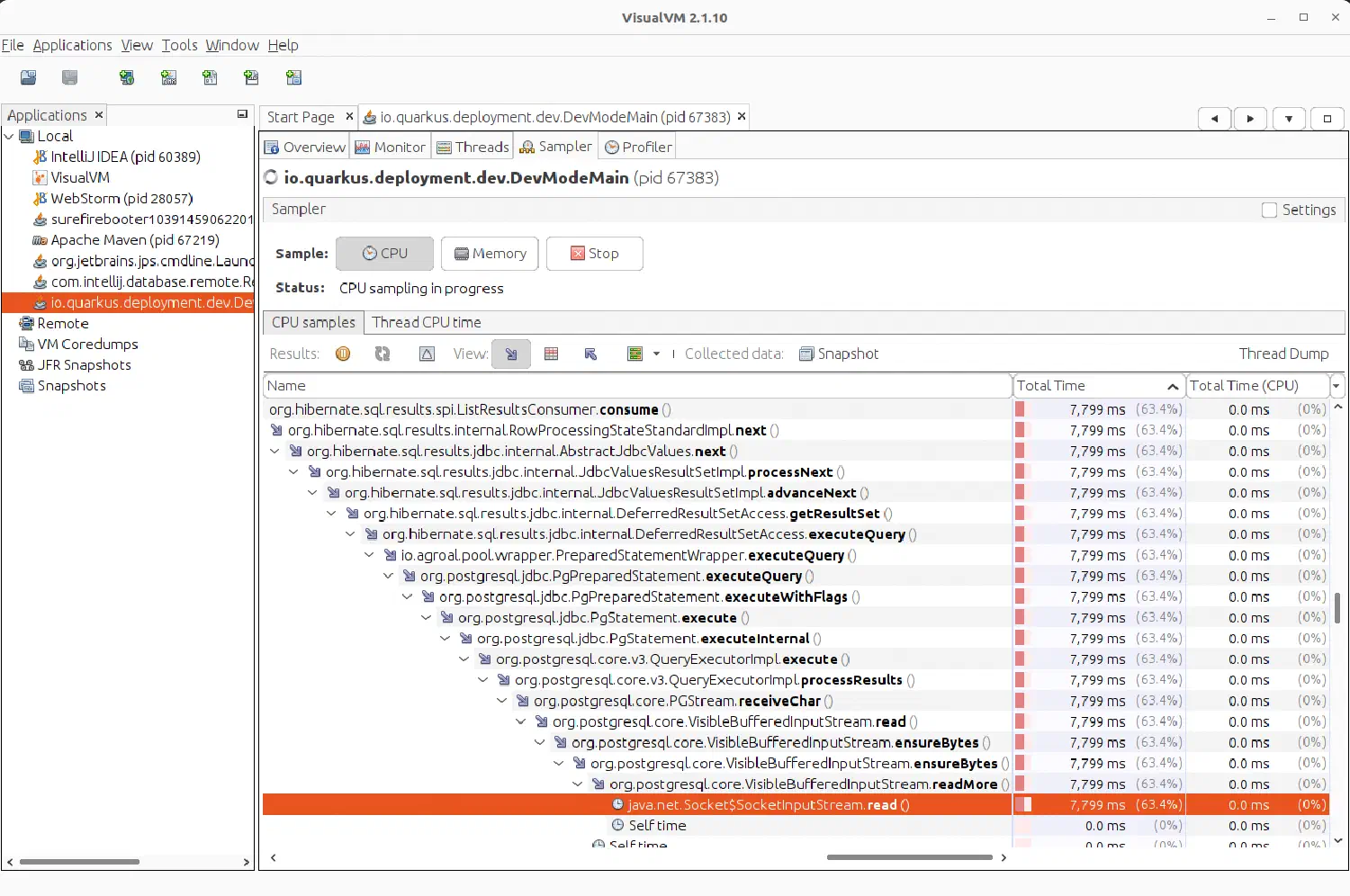
Im vorliegenden Fall fand ich heraus, dass die Kommunikation zur Datenbank die meiste Zeit in Anspruch nimmt: Von den 17 Sekunden ging fast die Hälfte aufs Konto der Datenbank. Setzen wir nun die Lupe darauf.
Der nächste Schritt ist das Herausfinden der exakten Datenbankanweisung.
Als Vorbereitung habe ich unser Programm so konfiguriert, dass sämtliche Anweisungen mitgeschrieben werden.
Dies habe ich mit der Anweisung quarkus.log.category."org.hibernate.type".level=TRACE in der Konfiguration der Applikation erreicht.
Mithilfe eines Debuggers konnte ich das Programm genau auf der Zeile pausieren, auf der die Abfrage als Nächstes abgesetzt wird. Im Bild unten ist die eingefärbte Zeile zu sehen. Der rote Punkt links zeigt an, dass der Debugger meine Bestätigung abwarten soll, bevor diese Zeile ausgeführt wird.

So fand ich heraus, welche Abfrage problematisch ist und konnte die Datenbankanweisung isolieren. In der Eingabe-Konsole der Datenbank konnte ich die Anweisung untersuchen.
SELECT
h1_0.id,
h1_0.bezeichnung,
h1_0.lockedGlobalId,
h1_0.vertragsAenderung_id
FROM
Geostruktur g1_0
JOIN
GeostrukturHierarchie h1_0
ON g1_0.id = h1_0.geostruktur_id
WHERE
g1_0.id = '720b4e96-d15e-498e-9c13-b84b1be5d952'
AND h1_0.id IN (
SELECT
g3_0.id
FROM
GeostrukturHierarchie g3_0
WHERE
g3_0.id IN (
SELECT
h2_0.id
FROM
GeostrukturHierarchie h2_0
WHERE
g1_0.id = h2_0.geostruktur_id
)
AND g3_0.aenderungAction IN ('CREATED', 'UPDATED', 'DELETED');
Bei dieser Anweisung werden zwei Tabellen zusammengeführt. Dabei wird spezifisch nach Informationen gefiltert, die bestimmte Bedingungen erfüllen. Wenn diese Tabellen allerdings tausende Einträge haben, dauert dieser Vorgang seine Zeit. Direkt auf der Datenbank ausgeführt erhielt ich das gleiche Ergebnis wie im Profiler: Es dauert jeweils zwischen 7 und 8 Sekunden, bis die Anweisung verarbeitet wurde.
Wieso dauert diese Abfrage jedoch so lange?
Normalerweise ist es für Datenbanken kein Problem, tausende Zeilen in einer Tabelle zu suchen.
Dafür wurden sie schliesslich gemacht.
Allerdings gibt es manchmal Abfragen, die kompliziert genug sind, dass diese plötzlich Sekunden statt Millisekunden dauern.
Mit der
SQL-Funktion EXPLAIN wird die Datenbank angewiesen, zu erklären, wie sie eine Anweisung ausführen wird.
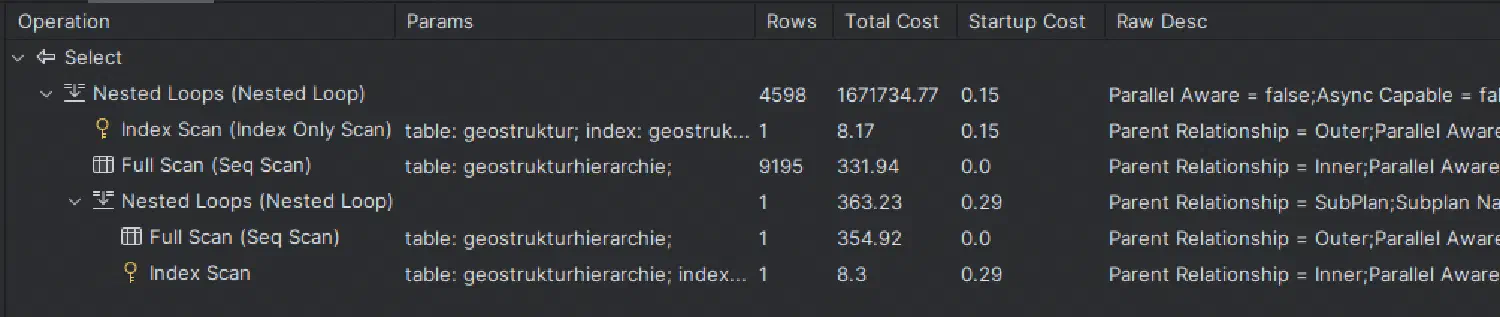
Das obige Bild zeigt auf, dass die Abfrage zu mehreren nested loops mit einem Full Scan über tausende Zeilen führt. Das treibt die Zahlen in der Spalte Total Cost in die Höhe. Dieser Wert widerspiegelt, wie aufwendig dieser Teil der Anweisung ist. Je aufwendiger eine Anweisung, desto länger dauert es, bis die Anweisung verarbeitet wird. Wenn wir nun die Total Cost reduzieren möchten, können wir versuchen, einen zusätzlichen Datenbank-Index anzulegen.
Was ist ein Index? Stell dir vor, du suchst in einem Fachbuch nach einer ganz bestimmten Information. Anstatt das ganze Buch zu durchsuchen, schaust du im Inhalts- oder im Stichwortverzeichnis nach. Dort findest du eine Referenz auf das gewünschte Kapitel oder sogar die konkrete Seite. So ähnlich funktioniert ein Datenbank-Index. Wir können über bestimmte Spalten in einer Tabelle einen Index anlegen. Statt sich jeden Eintrag anzusehen (der sogenannte Full Scan), kann die Datenbank stattdessen einen Index Scan machen – also sozusagen im Stichwortverzeichnis nachschauen statt die ganze Seite zu lesen.
Um die richtigen Indexe abzuleiten, musste ich die Suchkriterien in der Datenbankanweisung untersuchen. So kam ich auf folgende Indexes:
CREATE INDEX geostrukturhierarchie_geostruktur_id_ix
ON geostrukturhierarchie (geostruktur_id);
CREATE INDEX geostrukturhierarchie_aenderungaction_geostruktur_id_ix
ON geostrukturhierarchie (geostruktur_id, aenderungaction);
CREATE INDEX geostrukturhierarchie_aenderungaction_ix
ON geostrukturhierarchie (aenderungaction);
Ich habe in der Tabelle Geostrukturhierarchie drei neue Indexes erstellt. Mit Indexes können Abfragen, die regelmässig vorkommen, optimiert werden. Das heisst aber nicht, dass man jetzt zu viele Spalten in den Index nehmen soll, sonst verliert man Schreibleistung. Der Grund ist, dass bei jeder Änderung an den Daten in der entsprechenden Datenbanktabelle auch dessen Index aktualisiert werden muss.
Und das war es schon!
Die Analyse mittels EXPLAIN zeigt nun nur noch Index Scans an.
Dauerte die Abfrage vorher noch knapp acht Sekunden, sind es jetzt nur noch 45 Millisekunden.
Von den 17 Sekunden dauert die Speicheroperation alleine mit dieser Optimierung nur noch halb so lang.
Mit derselben Methode habe ich die restliche Dauer untersucht und optimiert.
Fazit
Als Erstes habe ich die Performance mit einem Profiler gemessen und herausgefunden, wo das Programm bei der Ausführung die meiste Zeit verliert.
Anschliessend habe ich die erste langsame Datenbankanweisung mittels Logausgaben und dem Debugger isoliert.
Mit EXPLAIN konnte mir die Datenbank aufzeigen, wie sie die Abfrage verarbeitet und wofür sie viel Zeit benötigt.
Diese Stellen habe ich mit einem neuen Index optimiert.
Das Resultat ist eine deutlich bessere Erfahrung beim Speichern der Geostrukturen für die Benutzenden.
